The slow road to persistence: encoding
This week I took on the large task of implementing a serialization scheme that allows saving the user’s scene onto their disk.
The problem at hand can divided in two major tasks:
- Serialize the scene by encoding its contents into some format.
- Deserialize the scene by decoding the format to recreate the original data.
I’ve chosen JSON as serialization format for representing the scene’s static data. That is, entities and components, along with all their properties and relationships are to be encoded into a JSON document that can then be used to create a perfect clone of the scene.
Why JSON? JSON is a well-known hierarchical file format that provides two good benefits: first, it’s easy for humans to read and hence debug. Second, it provides an uncanny 1:1 mapping to the concept of Entity and Component hierarchies.
It’s worth noting also that JSON tooling is excellent, providing the ability to quickly whip off a Python or Javascript utility that works on the file.
The downside is that reading and writing JSON is perhaps not as efficient as reading a custom binary format, however, I consider scene loading and saving an operation rare enough, most likely to be performed outside of the main game loop, so that it’s a feasible option at this time.
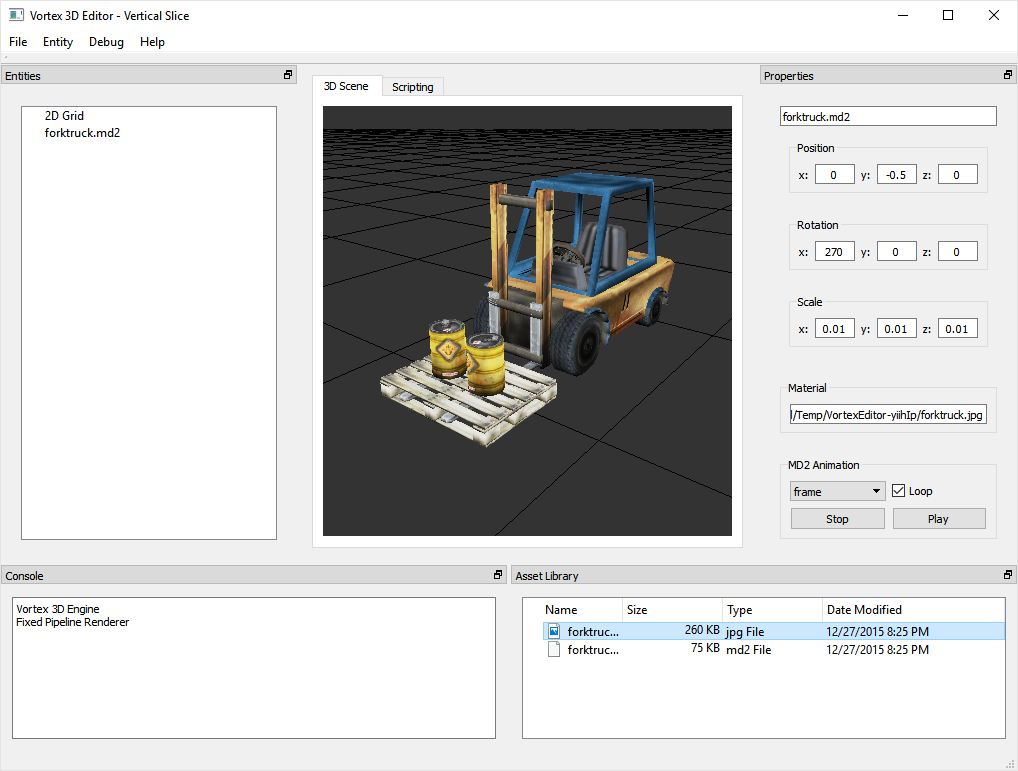
OK, so without further ado, let’s take a look at what a scene might look like once serialized. The following listing presents the JSON encoding of the scene depicted above. It was generated with the new vtx::JsonEncoder class.
{
"entities" : [
{
"children" : [],
"components" : [
{
"type" : 0
},
{
"type" : 1
}
],
"name" : "2D Grid",
"transform" : {
"position" : {
"x" : 0,
"y" : -0.5,
"z" : 0
},
"rotationEuler" : {
"x" : 0,
"y" : 0,
"z" : 0
},
"scale" : {
"x" : 1,
"y" : 1,
"z" : 1
}
}
},
{
"children" : [],
"components" : [
{
"type" : 0
},
{
"type" : 1
},
{
"type" : 100
}
],
"name" : "forktruck.md2",
"transform" : {
"position" : {
"x" : 0,
"y" : -0.5,
"z" : 0
},
"rotationEuler" : {
"x" : 4.7123889923095703,
"y" : 0,
"z" : 0
},
"scale" : {
"x" : 0.0099999997764825821,
"y" : 0.0099999997764825821,
"z" : 0.0099999997764825821
}
}
}
]
}
The document begins with a list of entities. Each entity contains a name, a transform, a list of children and a list of components. Notice how the transform is a composite object on its own, containing position, rotation and scale objects.
Let’s take a look at the encoded forktruck entity. We see its name has been stored, as well as its complete transform. In the future, when we decode this object, we will be able to create the entity automatically and place it exactly where it needs to be.
Now, you may have noticed that components look a little thin. Component serialization is still a work in progress and, at this time, I am only storing their types. As I continue to work on this feature, components will have all their properties stored as well.
On a more personal note, I don’t recall having worked with serialization/deserialization at this scale before. It’s definitely a challenge that’s already proven to be a large yet satisfying task. I am excited at the prospect of being able to save and transfer full scenes, perhaps even over the wire, and to a different device type.
The plan for next week is to continue to work on developing the serialization logic and getting started with the deserialization. Once this task is complete, we will be ready to move on to the next major task: the complete overhaul of the rendering system!
Stay tuned for more!